
मशीन लर्निंग कोई नई बात नहीं है। वास्तविक दुनिया के अनुप्रयोगों और स्टॉक की कीमतों में कृत्रिम बुद्धिमत्ता (AI) के उदय के साथ , आप सोच सकते हैं कि AI, मशीन लर्निंग और डेटा साइंस हाल ही के, अत्याधुनिक विचार हैं। हालाँकि वे निश्चित रूप से अत्याधुनिक हैं, लेकिन वे नए नहीं हैं।
मशीन लर्निंग शब्द का आविष्कार आईबीएम के कर्मचारी आर्थर सैमुअल ने 1959 में किया था। मशीन लर्निंग की शुरुआत(opens in a new tab) वास्तव में चेकर्स के खेल से हुई थी, जिसमें चेकर्स के मास्टर रॉबर्ट नेली को आईबीएम कंप्यूटर ने हरा दिया था। पिछले 60 वर्षों में, मशीन लर्निंग चेकर्स के खेल से कहीं अधिक परिष्कृत और प्रभावशाली बन गई है। वोल्ट एक्टिव डेटा, इंक. के अध्यक्ष और सीईओ डेविड फ्लावर का मानना है कि मशीन लर्निंग और रीयल-टाइम डेटा की शक्ति(opens in a new tab) “संगठनों को बेहतर निर्णय लेने और अधिक दक्षता के साथ काम करने में मदद कर सकती है, लेकिन वे भविष्य कहनेवाला विश्लेषण का उपयोग करके पैसे बचाने और नए राजस्व स्रोतों को अनलॉक करने में भी उनकी मदद कर सकते हैं।”

लेकिन मशीन लर्निंग आखिर है क्या? हर कोई इसके बारे में क्यों बात कर रहा है? आइए जानें! इस पोस्ट में, आप जानेंगे कि मशीन लर्निंग क्या है, यह कैसे काम करती है, और इसे रोज़मर्रा की ज़िंदगी के ज़्यादातर पहलुओं में कैसे शामिल किया जा रहा है।
मशीन लर्निंग क्या है?
मशीन लर्निंग(opens in a new tab) एआई का एक उपसमूह है जो डेटा और एल्गोरिदम का उपयोग करके मशीनों को “बुद्धिमान मानव व्यवहार की नकल करने” की क्षमता प्रदान करता है। एल्गोरिदम नियमों का एक समूह है जिसका उपयोग कंप्यूटर समस्याओं को हल करने के लिए करता है। मशीन लर्निंग एल्गोरिदम को पैटर्न और संबंधों को खोजने के तरीके सीखने के लिए बड़े पैमाने पर डेटा सेट पर प्रशिक्षित किया जाता है ताकि वे भविष्यवाणियां और निर्णय ले सकें। अनुभव और प्रशिक्षण डेटा की शुरूआत के साथ, वे बेहतर भविष्यवाणियां और निर्णय लेने के लिए समय के साथ सुधार कर सकते हैं।
आप सोच रहे होंगे कि यह वही है जो कंप्यूटर पहले से ही करता है। आप पूरी तरह से गलत नहीं होंगे। कंप्यूटर किसी कार्य को पूरा करने के लिए निर्देशों के एक स्पष्ट सेट का पालन करते हैं। आप एक वेब ब्राउज़र पर क्लिक करते हैं, और आपका कंप्यूटर इसे चालू करने के लिए चरण 1, 2, 3, और इसी तरह से गुजरने के लिए प्रोग्राम किया जाता है। मशीन लर्निंग थोड़ी अधिक सूक्ष्म है क्योंकि आपके कंप्यूटर को “एक विकल्प चुनना” होता है। मशीन लर्निंग में, कंप्यूटर को ढेर सारा डेटा और एक कार्य प्राप्त होता है। डेटा के साथ, कंप्यूटर को यह पता लगाना होता है कि कार्य को कैसे पूरा किया जाए।
आइए मशीन लर्निंग के वास्तविक दुनिया के उदाहरण पर नज़र डालें – चेहरे की पहचान। iOS फ़ोन पर, उपयोगकर्ता अपने फ़ोन को अपने चेहरे के सामने रखकर और स्क्रीन के संकेत के अनुसार उसे इधर-उधर घुमाकर चेहरे की पहचान सेट करते हैं। जैसे ही आप अपना चेहरा घुमाते हैं, फ़ोन डेटा एकत्र करता है: आपके जबड़े का कोण, आपके गालों की परिभाषा, आपकी आँखों के बीच की जगह, आदि। यह आपके चेहरे के बारे में सबसे छोटी-छोटी जानकारियों को नोट करता है ताकि यह अपना काम पूरा कर सके – हर बार जब आप स्क्रीन को अनलॉक करने का प्रयास करते हैं तो आपको पहचानना। चूँकि मशीन ने आपका चेहरा सीख लिया है , इसलिए यह तय कर सकती है कि आपका फ़ोन खुलेगा या नहीं, चाहे आप अपना रूप चश्मे जैसी किसी साधारण चीज़ से बदलें या फिर मास्क लगाएँ।
मशीन लर्निंग क्यों महत्वपूर्ण है?
कंपनियाँ अपने प्रोग्रामर और डेवलपर्स को अपने व्यावसायिक मॉडल और उत्पादों में मशीन लर्निंग को एकीकृत करने के तरीके खोजने के लिए प्रेरित कर रही हैं। क्यों? ऐसा इसलिए है क्योंकि अधिकांश लोग – जिनमें मैं भी शामिल हूँ – इसके लाभों को अनदेखा करना एक गलती मानेंगे। डेटा की अपार मात्रा और इसे तेज़ी से संसाधित करने की कंप्यूटर की क्षमता का उपयोग करके, मशीन लर्निंग लागत और सुरक्षा जोखिमों को कम कर सकती है, उत्पादों और सेवाओं को बेहतर बना सकती है, समय बचा सकती है और सटीकता और दक्षता को बढ़ा सकती है। ऐसा लग सकता है कि मशीन लर्निंग केवल तकनीकी उद्योग में ही फिट बैठती है, लेकिन यह सच से बहुत दूर है। मशीन लर्निंग तकनीक को किसी भी क्षेत्र में शामिल किया जा सकता है, और आप पाएंगे कि मशीन लर्निंग का उपयोग वित्त, स्वास्थ्य सेवा, शिक्षा, विपणन और साइबर सुरक्षा सहित अधिकांश उद्योगों में स्मार्ट प्रौद्योगिकीविदों द्वारा किया जा रहा है।
मशीन लर्निंग बनाम डीप लर्निंग बनाम न्यूरल नेटवर्क
जिस तरह से मशीन लर्निंग को एआई के बारे में बातचीत में आसानी से शामिल किया जाता है, वैसा ही डीप लर्निंग और मशीन लर्निंग के लिए भी होता है। आप “न्यूरल नेटवर्क” की उपस्थिति भी देख सकते हैं। ये शब्द – आर्टिफिशियल इंटेलिजेंस, मशीन लर्निंग, डीप लर्निंग और न्यूरल नेटवर्क – अक्सर एक साथ फेंके जाते हैं जैसे कि वे एक ही अर्थ साझा करते हैं, लेकिन ऐसा नहीं है।
जैसा कि हमने चर्चा की, मशीन लर्निंग AI का एक उपसमूह है, और डीप लर्निंग मशीन लर्निंग का एक उपसमूह है। डीप लर्निंग एक ऐसी तकनीक है जो कंप्यूटर को मानव मस्तिष्क और मानव निर्णय लेने की नकल करने के लिए डिज़ाइन की गई प्रक्रिया का पालन करने के लिए बहु-स्तरित एल्गोरिदम और तंत्रिका नेटवर्क का उपयोग करती है। हालाँकि तंत्रिका नेटवर्क शब्द विवादास्पद है – आलोचकों का तर्क है कि नाम एक कृत्रिम प्रक्रिया को मस्तिष्क के जैविक तंत्रिका नेटवर्क के साथ बहुत आसानी से भ्रमित करने की अनुमति देता है – एक कृत्रिम तंत्रिका नेटवर्क एक मशीन लर्निंग मॉडल है जो हमारे मस्तिष्क द्वारा सूचना को संसाधित करने के जटिल तरीके की नकल करने का प्रयास करके निर्णय लेता है। कृत्रिम तंत्रिका नेटवर्क एक स्तरित तरीके से काम करते हैं, एल्गोरिदम की एक जटिल प्रणाली स्थापित करते हैं जो कंप्यूटर के लिए “मनुष्यों की तरह सोचना” संभव बनाता है क्योंकि एल्गोरिदम डेटा को संसाधित करते हैं, सीखते हैं और सुधार करते हैं।

मशीन लर्निंग एल्गोरिदम के प्रकार
मशीन लर्निंग पूर्वानुमान लगाने के लिए एल्गोरिदम का उपयोग करती है। याद रखें – मशीन लर्निंग एल्गोरिदम मापदंडों का एक सेट है जिसका उपयोग कंप्यूटर दिए गए डेटा सेट से सीखने और पूर्वानुमान लगाने या निर्णय लेने के लिए करते हैं। ये एल्गोरिदम डेटा को प्रशिक्षित करने और उसका विश्लेषण करने के लिए अलग-अलग तरीकों का उपयोग करते हैं ताकि इसके पूर्वानुमान सटीक हों। समय के साथ नए डेटा को पेश करके, ये एल्गोरिदम मशीनों को अधिक सटीक या स्मार्ट बनने में मदद करते हैं। आप यह भी कह सकते हैं कि मशीनें – या कंप्यूटर – अधिक (कृत्रिम!) बुद्धिमत्ता प्राप्त करते हैं ।
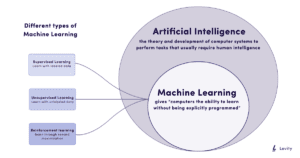
मशीन लर्निंग एल्गोरिदम चार प्रकार के होते हैं: पर्यवेक्षित, अर्ध-पर्यवेक्षित, अपर्यवेक्षित और सुदृढ़ीकरण।
देखरेख
सुपरवाइज्ड लर्निंग मशीनों को इनपुट और (opens in a new tab)वांछित आउटपुट प्रदान करके प्रशिक्षित करने के लिए लेबल किए गए डेटा का उपयोग करता है। “वांछित” महत्वपूर्ण है क्योंकि आप चाहते हैं कि कंप्यूटर सटीक और प्रासंगिक परिणाम दे। एल्गोरिदम को यह पता लगाने की आवश्यकता है कि इनपुट से जानकारी कैसे ली जाए और वांछित आउटपुट की भविष्यवाणी कैसे की जाए। इस पद्धति में, एल्गोरिदम डेटा का विश्लेषण करता है, किसी भी पैटर्न को उठाता है, और भविष्यवाणियां करता है। जब एल्गोरिदम भविष्यवाणियां करता है, तो इसकी सटीकता को मापा जाता है और सही किया जाता है। सुपरवाइज्ड लर्निंग एल्गोरिदम अपनी त्रुटियों को कम करने और अपनी भविष्यवाणियों को बेहतर बनाने के लिए बार- बार इस प्रक्रिया से गुजरते हैं।
पूर्वानुमान लगाने के लिए दो प्रकार के पर्यवेक्षित मशीन लर्निंग मॉडल का उपयोग किया जाता है – वर्गीकरण और प्रतिगमन।
- वर्गीकरण: एक मशीन लर्निंग एल्गोरिदम जो डेटा का विश्लेषण करके उन्हें श्रेणियों में डालता है। वर्गीकरण का एक उदाहरण स्पैम का पता लगाना है जब कोई ईमेल आपके इनबॉक्स या स्पैम फ़ोल्डर में फ़िल्टर किया जाता है। वर्गीकरण एल्गोरिदम में निर्णय वृक्ष, यादृच्छिक वन, k-निकटतम पड़ोसी और समर्थन वेक्टर मशीनें शामिल हैं।
- रिग्रेशन: चरों के बीच संबंधों को समझने के लिए एक मशीन लर्निंग एल्गोरिदम। रिग्रेशन एल्गोरिदम का उपयोग आश्रित और स्वतंत्र चरों के बीच अनुमान लगाने के लिए किया जाता है, उदाहरण के लिए, आप किसी व्यवसाय के लिए बिक्री का पूर्वानुमान कैसे लगाएंगे। सामान्य रिग्रेशन एल्गोरिदम रैखिक रिग्रेशन और लॉजिस्टिक रिग्रेशन हैं।
जब आप किसी सवारी को बुलाते हैं, तो Uber(opens in a new tab) जैसी कंपनी आपके लिए अनुभव को थोड़ा आसान बनाने के लिए मशीन लर्निंग का उपयोग करती है। न्यूयॉर्क जैसे शहर में, यदि आप पीली टैक्सी कैब का उपयोग करते हैं, तो आपको कभी नहीं पता होता कि आप यात्रा के लिए कितना भुगतान कर रहे हैं जब तक आप वहां नहीं पहुंच जाते। आइए आशा करते हैं कि आप ट्रैफ़िक में न फँसें! ताकि Uber पहले से ही किराए का अनुमान दे सके, उनकी AI टीम “रैखिक से लेकर गहन शिक्षण मॉडल तक की तकनीकों का लाभ उठाती है” और ढेर सारा विशिष्ट डेटा इकट्ठा करती है—पिकअप और ड्रॉपऑफ़ पॉइंट, अनुरोध का समय, ट्रैफ़िक पैटर्न, मौसम और ऐतिहासिक डेटा—ताकि आपको अपनी सवारी की पुष्टि करने से पहले लागत का पता चल जाए।
के चलते किसी
अनसुपरवाइज्ड लर्निंग मशीन लर्निंग एल्गोरिदम का उपयोग करके लेबल रहित डेटा का विश्लेषण करता है। यह डेटा के भीतर समानताओं या संबंधों के बारे में – मानवीय हस्तक्षेप के बिना – पैटर्न की खोज और पहचान करने की अनुमति देता है। अनसुपरवाइज्ड लर्निंग एल्गोरिदम डेटा को उन श्रेणियों में व्यवस्थित और समूहित करेगा जो समझ में आते हैं।
अप्रशिक्षित शिक्षण के सामान्य प्रकार क्लस्टरिंग और आयाम न्यूनीकरण हैं।
- क्लस्टरिंग: एक तकनीक जिसमें एल्गोरिदम लेबल रहित डेटा में पैटर्न खोजते हैं और सूचनाओं को उनके सहसंबंध के आधार पर समूहीकृत करते हैं। K-मीन्स एक सामान्य अप्रशिक्षित क्लस्टरिंग एल्गोरिथम है।
- आयाम न्यूनीकरण: एक तकनीक जिसमें एल्गोरिदम डेटा सेट में चरों या आयामों को कम कर देता है ताकि इसे अधिक प्रबंधनीय बनाया जा सके।
कल्पना करें कि एक ई-कॉमर्स कंपनी Facebook विज्ञापनों के ज़रिए नए ग्राहकों को लक्षित करना चाहती है। Facebook (अब मेटा) के पास अपने उपयोगकर्ताओं के बारे में बड़ी मात्रा में डेटा होने के कारण, यह पैटर्न पहचान और सूचना वर्गीकरण के लिए जानकारी का विश्लेषण करने के लिए संभवतः अप्रशिक्षित शिक्षण एल्गोरिदम का उपयोग करता है। यह ग्राहक डेटा को आयु, स्थान या उनकी खर्च करने की आदतों के आधार पर समूहीकृत करने जैसा लग सकता है। इस जानकारी के साथ, विज्ञापनदाता अलग-अलग दर्शकों के लिए लक्षित विज्ञापन बना सकते हैं – उदाहरण के लिए, एक समूह के लिए छवि विज्ञापन और दूसरे के लिए वीडियो विज्ञापन।
अर्द्ध निगरानी
अर्ध-पर्यवेक्षित मशीन लर्निंग,(opens in a new tab) पर्यवेक्षित और अपर्यवेक्षित लर्निंग का एक संकर है। इन एल्गोरिदम को लेबल किए गए और लेबल रहित डेटा पर प्रशिक्षित किया जाता है। यह मशीन लर्निंग के लिए एक सामान्य समाधान है जब आप बड़ी मात्रा में लेबल किए गए डेटा पर समय और पैसा बचाना चाहते हैं, जैसा कि आपको पर्यवेक्षित लर्निंग के लिए चाहिए। लेबल रहित डेटा प्राप्त करना आसान है, लेकिन अर्ध-पर्यवेक्षित लर्निंग अभी भी पर्यवेक्षित कार्यों के लिए प्रशिक्षण देना संभव बनाता है जिन्हें वर्गीकरण और प्रतिगमन की आवश्यकता होती है।
सुदृढीकरण
सुदृढीकरण मशीन लर्निंग एक ऐसी तकनीक है जो एल्गोरिदम को प्रशिक्षित करने के लिए परीक्षण और त्रुटि का उपयोग करती है। एल्गोरिदम नमूना डेटा का उपयोग नहीं करता है। इसके बजाय, यह विकल्पों का पता लगाने और सर्वोत्तम समाधान तय करने के लिए परिणामों का मूल्यांकन करने के लिए मापदंडों के एक सेट का उपयोग करता है – जैसे कि आप गेम खेलते समय सीख सकते हैं। संक्षेप में, सुदृढीकरण एल्गोरिदम चलते-चलते सीखते हैं। मॉडल बेहतर अनुशंसाओं के लिए प्रशिक्षित करने के लिए सकारात्मक सुदृढीकरण का उपयोग करते हैं। जब यह एक सफल कार्रवाई या परिणाम देता है, तो इसे सुदृढ़ किया जाता है। और जब ऐसा नहीं होता है, तो इसे अनदेखा कर दिया जाता है।
सुदृढीकरण सीखने का(opens in a new tab) एक लोकप्रिय उदाहरण वह है जब आईबीएम वाटसन® प्रणाली ने 2011 में जेपार्डी! जीता था । परीक्षण और त्रुटि प्रशिक्षण के माध्यम से, वाटसन यह पता लगाने में सक्षम था कि उसे कब उत्तर देने का प्रयास करना चाहिए, उसे कौन सी श्रेणी चुननी चाहिए, और कितना पैसा दांव पर लगाना चाहिए।
8 ज़रूरी मशीन लर्निंग एल्गोरिदम
मशीन लर्निंग बहुत तकनीकी है, और यह और भी तकनीकी हो जाती है जब आप उन कई तरीकों पर विचार करते हैं जिनसे कंप्यूटर को पूर्वानुमान और निर्णय लेने के लिए प्रशिक्षित किया जा सकता है। जैसे-जैसे आप मशीन लर्निंग में आगे बढ़ेंगे, आपको दर्जनों एल्गोरिदम मिलेंगे, लेकिन यहाँ मशीन लर्निंग के लिए आठ सबसे आम एल्गोरिदम दिए गए हैं जिन्हें आपको जानना चाहिए।
रेखीय प्रतिगमन
एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम जो दो चरों के बीच पूर्वानुमान लगाता है – एक इनपुट और एक लक्ष्य चर। यह डेटा बिंदुओं का उपयोग करता है और उन्हें यथासंभव सर्वोत्तम तरीके से एक रेखा में फिट करता है। यह “प्रतिगमन रेखा” चरों के बीच संबंधों का विश्लेषण करने में मदद करती है, जिससे इनपुट मानों के आधार पर आउटपुट की भविष्यवाणी करना संभव हो जाता है। रैखिक प्रतिगमन एल्गोरिदम का उपयोग आवास की कीमतों की भविष्यवाणी करने, बिक्री का पूर्वानुमान लगाने और रुझानों का विश्लेषण करने में किया जाता है।
संभार तन्त्र परावर्तन
पूर्वानुमान और वर्गीकरण में उपयोग किया जाने वाला एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम। लॉजिस्टिक रिग्रेशन एल्गोरिदम का उपयोग संभावनाओं की भविष्यवाणी करके इनपुट डेटा को श्रेणियों में क्रमबद्ध करने के लिए किया जाता है। इसका उपयोग आमतौर पर बाइनरी कार्यों के लिए किया जाता है – डेटा को दो समूहों में से एक में वर्गीकृत करना – उदाहरण के लिए, क्या यह कुत्ते की तस्वीर है? हाँ/नहीं? लॉजिस्टिक रिग्रेशन एल्गोरिदम के सामान्य उपयोग स्पैम और धोखाधड़ी का पता लगाने में हैं। क्या यह ईमेल स्पैम है? हाँ/नहीं?
निर्णय वृक्ष
वर्गीकरण और प्रतिगमन के लिए उपयोग किया जाने वाला एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम। निर्णय वृक्ष एल्गोरिदम डेटा सेट के बारे में एक प्रश्न – एक रूट नोड – से शुरू होते हैं। जैसे-जैसे आप डेटा के बारे में अधिक प्रश्न पूछते हैं, यह आंतरिक नोड्स या संभावित परिणामों में शाखाबद्ध होता जाता है। ये प्रश्न या तो बाइनरी (दो विकल्पों के साथ) या मल्टी-लीनियर (कई विकल्पों के साथ) होते हैं। निर्णय वृक्ष एल्गोरिदम की गणना तब पूरी होती है जब प्रत्येक नोड एक लीफ नोड में समाप्त होता है जहां एल्गोरिदम डेटा पर अंतिम निर्णय लेता है। अगर यह एक नियमित निर्णय वृक्ष की याद दिलाता है, तो ऐसा इसलिए है क्योंकि यह है! मशीन लर्निंग में निर्णय वृक्ष किसी भी निर्णय वृक्ष की तरह ही होते हैं जिसे आप अपने लिए लिखेंगे, लेकिन बस अधिक जटिल होते हैं! निर्णय वृक्ष एल्गोरिदम के वास्तविक जीवन के उदाहरण ऋण आवेदन मूल्यांकन (सोचें: अभी खरीदें, बाद में भुगतान करें जैसे Affirm प्लेटफ़ॉर्म) और मेडिकल डायग्नोस्टिक सॉफ़्टवेयर में पाए जाते हैं।
यादृच्छिक वन
वर्गीकरण और प्रतिगमन कार्यों के लिए एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम। रैंडम फ़ॉरेस्ट एल्गोरिदम कई निर्णय वृक्ष एल्गोरिदम से बने होते हैं जिन्हें बैगिंग विधि से प्रशिक्षित किया गया है। बैगिंग एक ऐसी विधि है जहाँ प्रत्येक निर्णय वृक्ष को उसकी सटीकता में सुधार करने के लिए डेटा पर स्वतंत्र रूप से और यादृच्छिक रूप से प्रशिक्षित किया जाता है। कई निर्णय वृक्ष एक “रैंडम फ़ॉरेस्ट” में विकसित होते हैं जहाँ उनके अंतिम नोड्स – या आउटपुट – एक भविष्यवाणी के लिए औसत किए जाते हैं।
बैंकिंग में रैंडम फ़ॉरेस्ट एल्गोरिदम का इस्तेमाल आम तौर पर किया जाता है। सवालों और उनके संभावित परिणामों का मूल्यांकन करके, बैंक इस एल्गोरिदम का इस्तेमाल लोन आवेदनों में कर सकते हैं – और यह तय कर सकते हैं कि कौन अपने कर्ज चुकाने की सबसे ज़्यादा संभावना रखता है – और धोखाधड़ी का पता लगा सकते हैं।
नैवे बेयस
वर्गीकरण के लिए उपयोग किया जाने वाला एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम। यह गणितीय सूत्र, बेयस प्रमेय पर आधारित है, जिसका उपयोग सशर्त संभावनाओं या किसी घटना के घटित होने की संभावना की गणना करने के लिए किया जाता है। नैवे बेयस एल्गोरिदम इस पर एक स्पिन लगाता है ताकि डेटा को एक चीज़ या किसी अन्य के रूप में वर्गीकृत किए जाने की संभावना की गणना की जा सके। एल्गोरिदम को एक कारण से “नैवे” कहा जाता है। यहां तक कि जब डेटा दिया जाता है जो एक साथ प्रतीत होता है, तो यह प्रत्येक को स्वतंत्र रूप से मानता है।
उदाहरण के लिए, यदि किसी फल की तस्वीर दी जाए, तो यह उस वस्तु को पीले, आयताकार और 2-3 इंच व्यास में एक दूसरे से स्वतंत्र मान लेगा। फिर एल्गोरिथ्म इन विशेषताओं को संयोजित करके वस्तु के नींबू होने की संभावना पर विचार करता है। नैव बेयस एल्गोरिदम विशेष रूप से बड़े डेटा सेट पर उपयोगी होते हैं और इनका उपयोग छवि वर्गीकरण, चैटबॉट, ईमेल फ़िल्टरेशन और भावना विश्लेषण के लिए किया जाता है – यह निर्धारित करने के लिए कि संदेश का स्वर सकारात्मक, नकारात्मक या तटस्थ है।
सपोर्ट वेक्टर मशीन (एसवीएम)
एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम जो आमतौर पर वर्गीकरण के लिए उपयोग किया जाता है, लेकिन इसे प्रतिगमन कार्यों पर भी लागू किया जा सकता है। सपोर्ट वेक्टर मशीन (SVM) एल्गोरिदम का उपयोग “हाइपरप्लेन” खोजने के लिए किया जाता है। हाइपरप्लेन एक निर्णय सीमा है जो इनपुट डेटा को अलग-अलग समूहों में अलग करती है। जब एल्गोरिदम में नया डेटा पेश किया जाता है, तो इसे इसकी समानताओं के आधार पर हाइपरप्लेन के दोनों ओर क्रमबद्ध किया जाता है। लक्ष्य नए डेटा को बेहतर ढंग से वर्गीकृत करने के लिए समूहों के बीच मार्जिन को जितना संभव हो उतना बड़ा बनाना है।
एसवीएम एल्गोरिदम का एक लोकप्रिय वास्तविक जीवन अनुप्रयोग हस्तलेखन पहचान में उपयोग किया जाता है। “यू” और “वी” अक्षरों पर विचार करें। जब एसवीएम एल्गोरिदम को डेटा पर प्रशिक्षित किया जाता है, तो वे प्रत्येक लिखित अक्षर के भीतर समानताओं को देखते हैं। जितना अधिक डेटा पेश किया जाता है, एल्गोरिदम उन लिखित विशेषताओं के बीच अंतर को चौड़ा करने में सक्षम होता है जो “यू” और अन्य जो “वी” को निर्धारित करते हैं।
K-निकटतम पड़ोसी (KNN)
एक पर्यवेक्षित मशीन लर्निंग एल्गोरिदम जिसका उपयोग वर्गीकरण कार्यों में सबसे अधिक किया जाता है। डेटा बिंदुओं का विश्लेषण करके, KNN एल्गोरिदम डेटा को समूहीकृत करने या उनके बारे में पूर्वानुमान लगाने के लिए बिंदुओं की निकटता का उपयोग करता है। यह ऐसा करने में सक्षम है क्योंकि एल्गोरिदम मानता है कि समान डेटा बिंदु पास में होंगे। वर्गीकरण के दौरान, एल्गोरिदम “K” को देखता है, जो विचार करने के लिए निकटतम पड़ोसियों की संख्या है।
कल्पना करें कि आप लेबल वाले बिंदुओं को देख रहे हैं जो नीले और हरे रंग के ग्रेडिएंट स्केल पर चिह्नित हैं। जब एल्गोरिदम में कोई नया डेटा पॉइंट पेश किया जाता है, तो एल्गोरिदम विचार करने के लिए निकटतम पड़ोसियों की संख्या को देखेगा, या जो भी “K” है। मान लें कि “K” 10 है। यदि नया डेटा पॉइंट तीन नीले बिंदुओं और सात हरे बिंदुओं के करीब है, तो एल्गोरिदम उस बिंदु को हरा मान लेगा। जब “K” अधिक होता है, तो एल्गोरिदम अपने पूर्वानुमानों के औसत से अधिक सटीक परिणाम दे सकता है। अतिरिक्त बिंदु परिणामों को तिरछा कर सकते हैं , लेकिन निकटतम डेटा बिंदुओं को किसी भी आउटलेयर को पूर्वानुमानों को नकारात्मक रूप से प्रभावित करने से रोकने के लिए उच्चतर भार दिया जाना चाहिए।
आप आमतौर पर K-निकटतम पड़ोसी एल्गोरिदम का उपयोग उन सेवाओं में देखेंगे जो आपके उपयोगकर्ता अनुभव के आधार पर अनुशंसा प्रणाली बनाती हैं। नेटफ्लिक्स, अमेज़ॅन और यूट्यूब के बारे में सोचें।
कश्मीर साधन
क्लस्टरिंग के लिए इस्तेमाल किया जाने वाला एक अप्रशिक्षित मशीन लर्निंग एल्गोरिदम। K-मीन्स एक अप्रशिक्षित एल्गोरिदम है, जिसका मतलब है – अगर आपको याद हो – कि सारा डेटा लेबल रहित है। जैसा कि नाम से पता चलता है, यह K-निकटतम पड़ोसियों के समान है, जिसमें यह पैटर्न की खोज करने और समान डेटा को एक ही क्लस्टर में समूहित करने के लिए डेटा की निकटता का उपयोग करता है।
K-मीन्स एल्गोरिथम के लिए, “K” एक सेंट्रोइड है – एक डेटा बिंदु जो प्रत्येक क्लस्टर के केंद्र (या माध्य) का प्रतिनिधित्व करता है। प्रशिक्षण के दौरान एल्गोरिदम का लक्ष्य क्लस्टर में सेंट्रोइड और डेटा बिंदुओं के बीच की दूरी को कम करना है। इससे क्लस्टर बनाने में मशीन की सटीकता बढ़ेगी क्योंकि अधिक डेटा पेश किया जाता है।
के-मीन्स क्लस्टरिंग विशेष रूप से खुदरा क्षेत्र में सहायक है, जब कंपनियाँ अपने ग्राहकों को उनके खरीद व्यवहार के आधार पर वर्गीकृत करना चाहती हैं। इस एल्गोरिदम का उपयोग धोखाधड़ी का पता लगाने और डिलीवरी ज़ोन को अनुकूलित करने के लिए भी किया जाता है।

मशीन लर्निंग – वास्तविक दुनिया में
आपको शायद इसका एहसास न हो, लेकिन आप लगभग हर दिन मशीन लर्निंग का उपयोग करने वाले अनुप्रयोगों से अवश्य ही रूबरू होते होंगे। मशीन लर्निंग आपके द्वारा उपयोग की जाने वाली तकनीक की एक विशाल श्रृंखला में अंतर्निहित है, जिसमें स्मार्टफ़ोन, सोशल मीडिया और ईमेल शामिल हैं। एल्गोरिदम द्वारा संभव की जाने वाली भविष्यवाणियाँ और निर्णय लेने की प्रक्रिया के वास्तविक दुनिया में बहुत से उपयोग हैं। वास्तविक दुनिया में मशीन लर्निंग के उदाहरणों में शामिल हैं:
- चेहरे की पहचान
- वाक् पहचान
- प्राकृतिक भाषा प्रसंस्करण
- अनुशंसा इंजन
- ईमेल स्वचालन/स्पैम फ़िल्टरिंग
- सोशल मीडिया कनेक्शन
- धोखाधड़ी का पता लगाना
- शेयर बाज़ार की भविष्यवाणियाँ
- संभावी लेखन
- भविष्य बतानेवाला विश्लेषक
- आभासी व्यक्तिगत सहायक
- यातायात पूर्वानुमान
- स्वयंचालित कारें
- चिकित्सा निदान
मशीन लर्निंग का भविष्य
क्योंकि मशीन लर्निंग वह तरीका है जिससे मनुष्य कंप्यूटर को पूर्वानुमान और निर्णय लेकर मानव व्यवहार की नकल करने के लिए प्रोग्राम करता है, आप इसे AI में “मानव बुद्धिमत्ता” के पीछे का रहस्य मान सकते हैं। जबकि हम घरेलू वैक्यूम क्लीनर में रोबोटिक्स में इसकी भूमिका की सराहना कर सकते हैं या यह हमारे प्राथमिक ईमेल इनबॉक्स से स्पैम को फ़िल्टर करता है, मशीन लर्निंग का संभावित प्रभाव दुनिया को बदलने वाला है। यह डॉक्टरों को तेज़ और अधिक सटीक चिकित्सा निदान करने में मदद कर सकता है। यह रक्षा की पहली पंक्ति हो सकती है जो किसी हैकर को आपकी मेहनत की कमाई के हज़ारों डॉलर चुराने से रोकती है। यह साइबरबुलिंग के खिलाफ़ एक रक्षक है जहाँ इसका उपयोग हानिकारक संदेश साझा करने वाले उपयोगकर्ताओं को फ़्लैग करने, ब्लॉक करने और प्रतिबंधित करने के लिए किया जा सकता है।
यदि आप आर्टिफिशियल इंटेलिजेंस में करियर बनाने में रुचि रखते हैं, तो यह कहना सुरक्षित है कि AI कहीं नहीं जा रहा है। और मशीन लर्निंग करियर बनाने के लिए इसके सबसे लोकप्रिय तरीकों में से एक है। लेकिन आपको पहले कहीं से शुरुआत करनी होगी। स्किलक्रश ब्रेक इनटू टेक प्रोग्राम एक वेब डेवलपर के इन-डिमांड स्किल्स – पायथन, जावास्क्रिप्ट, डेटा एनालिसिस – को सीखने का पहला कदम है ताकि आप मशीन लर्निंग में AI इंजीनियर बनने की दिशा में काम कर सकें।